
英语原文共 20 页,剩余内容已隐藏,支付完成后下载完整资料
基于运动线索聚类的人群密度估计方法
摘要
由于大型聚集人群有着复杂的情况,利用视频监控分析人群行为是现在的热门研究方向。在理解人群行为方面,特定区域的自动化视频监控是人群密度估计是一个不可缺少的工具。人群密度估计能在规定的时间内提供一个特定区域的人群数量信息。现有的大多数计算机视觉方法使用监督训练到达密度估计,但是我们提出了一种新的方法,即利用运动线索和分层聚类来实现人群密度估计。这种方法首先利用光流信息进行运动估计,然后分析轮廓用于人群轮廓检测,最后通过聚类来得到人群密度。该方法在墨尔本板球场(MCG)和两个公开可用的数据集进行了数据采集测试,这两个数据集是人群的跟踪和监控性能评价(PETS)2009和加利福尼亚大学的圣迭戈(UCSD),并且是在不同人群密度行人交通数据库(中、高密度人群)和不同的条件(存在部分遮挡等)下分别验证的。在MCG和PETS上得到的最大误差是3.62,UCSD上得到的最大误差是2.66,因此我们所提出的方法能准确的进行人群密度估计。对于PETS(2009)上50%的数据,本文提出的方法要比现有的方法更加具有优越性。
关键词:视频监控,人群密度估计,人数统计,人群监控,光流,聚类
1 绪论
监控人群并了解人群行为一直是目前最前沿的研究。人群监控的目标是保障公共场所(如音乐会、商场、人行道、城市街道、机场、公共运输终端、体育场馆、奥运会等)的人员安全;更重要的是,在火灾事件、自然灾害、建筑物倒塌等情况下急救人员撤离。在火灾、踩踏事件,暴力聚集事件等不同的情况下,我们需要在不同的区域进行人群密度估计。从不断运动的视频中对于某个集中区域采用人工计数是非常繁琐的,但这依然是目前广泛采用的方法。持续不断的监视,会使人员感到疲惫,而且在突发情况中,很难实现实时监控和及时处理。
为了帮助解决人工计数存在的问题,一些人群检测,计数和跟踪的算法已经给出了一些成果。可以发现在[80]中,有着系统的人类活动行为的认识。在封闭环境跟踪目标过程中存在人群遮挡现象和同一对象无法再现等困难,这些算法误差会很大。采用计数方式的检测算法需要定位到个体目标,而直接进行密度估计的算法不需要个体信息,人群的映射特征和人群密度之间有一定的关系。在公共场所进行人群监控,因为遮挡现象使得实现目标匹配很困难,依靠定位个体并跟踪的方法来统计人数是不理智的。
公共场所人群监控的目的是提供合理的密度估计结果并规划人群疏散路线。ZHAN等人[92]和Jacques等人[41]指出了人群研究的重要性,并展示了他们进行大型人群管理的成果(如公共场所空间的设计、虚拟环境、画面监控和智能环境的创造)。人群检测面临的困难是在不同的环境条件下检测运动目标,不均匀的光照和阴影、人群的非刚性动态走势和相互遮挡是几个主要方面[90],这些主要是因为人体的非刚性运动。人体作为一个非刚性物体,有着弹性和流体运动特征。归结起来,目标检测和跟踪面临的挑战有:(1)信息损失(从3维到2维);(2)视频存在噪声;(3)非刚性运动(关节);(4)相互遮挡,自身物体遮挡,部分遮挡和完全遮挡;(5)对象运动随机性;(6)非均匀光照场景;(7)实时处理的苛刻要求。
目前视频监控系统主要运用于公路汽车的检测和跟踪,也有些运用到人群监控,但是在面对高密度人群时很难解决问题。单一目标的检测和跟踪,高密度情况下比低密度情况要困难得多,此外,人体的非刚性运动更是增加了难度。非刚性运动指的是物体运动不连贯,不同部位运动方式不同(如不同的移动方向和速度),而刚性运动(如汽车)遵循着运动相干性(整体运动方向速度一致)。因此,应用于车辆检测跟踪的技术如果不做改进是无法运用到互相遮挡的人群监测中去的。为了实现人群监控,不断学习、分析和改善算法程序是十分重要的。
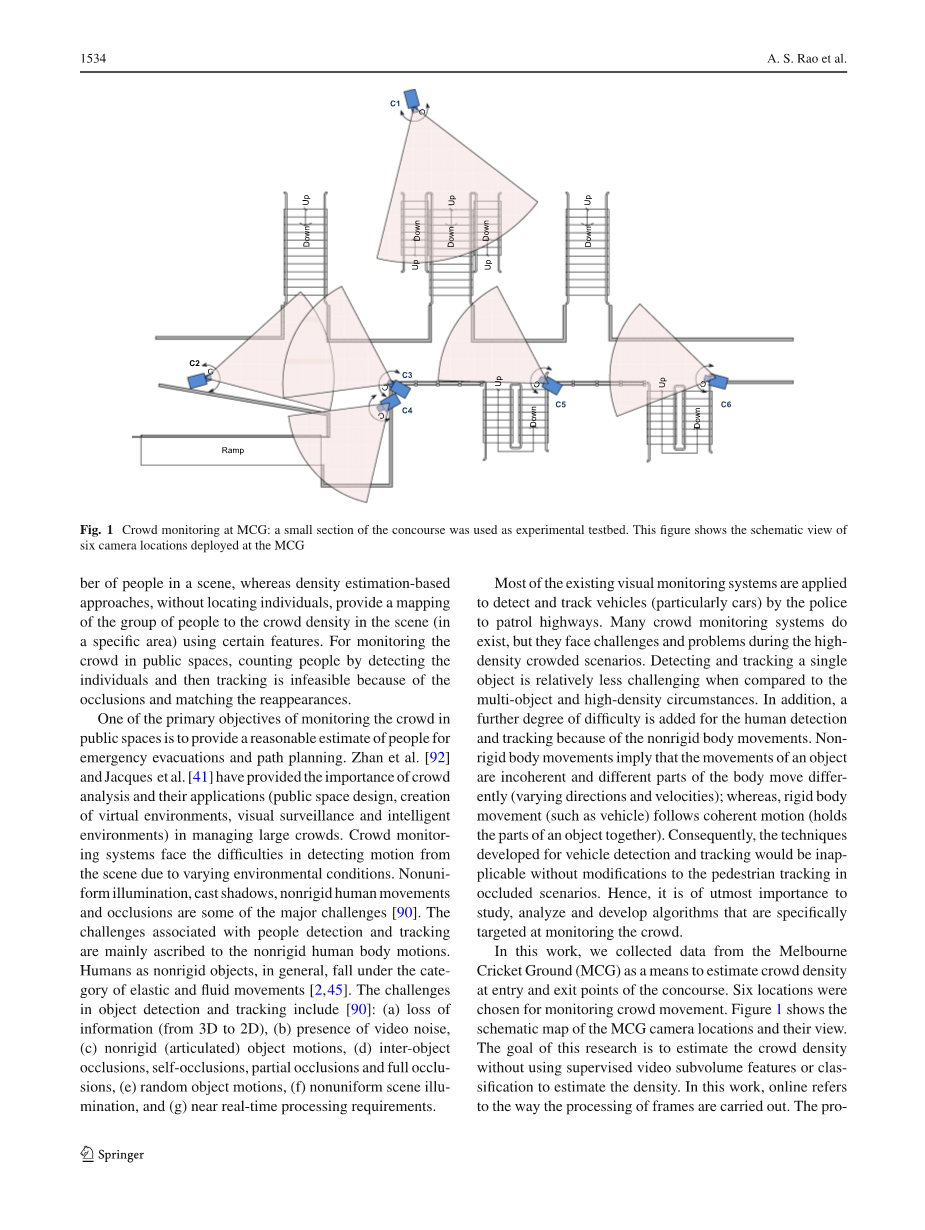
图1 摄像头位置信息和场景信息
在本文中,我们采用MCG的数据,进场和出场点一共六个区域的监控视频,进行人群密度估计。图1显示了MCG摄像头位置信息和场景信息,这个研究的目的不是要借助监控视频的分卷和分类功能,也不是根据已经确认视频可用性后的批量图像处理,而是根据实时监控中部分图像进行逐帧处理估计人群密度。与已有的研究不同的是,本文采用从全部视频序列中提取的人群特征进行训练和分类来实现密度估计。在这方面我们采用基于光流信息的人群密度估计,依靠光流运动估计作为主要方式来推到整个结果,结合不同的信号处理模块、滤波器和数学分析理论进行实时密度估计。拥挤场景中的运动目标跟踪和人群行为分析方面,我们认为本项工作为未来的研究提供了基础。该方法已经MCG的弱光照、严重遮挡现象和低画质视频中测试过了,为了进一步验证方法的可行性,采用PETS和UCSD的高密度人群视频,在存在阴影和严重遮挡的情况下进行测试。这些视频中只包含人物前景,因此假定检测目标只有人物。为了区分车辆,人物,动物和其他物品,此方法需要另外添加检测和分类步骤,这不是本文的主要研究。本文提出的方法主要有两个方面优点:(1)不同于背景建模,模型匹配和纹理分析的方法,利用运动特征计算人群密度;(2)进行的是现场实时监控估计密度,而不是采用录好的视频。
第2节介绍了相关的背景建模、运动估计、人体建模、头部检测和人群密度估计方法;第3节提出了所用方法的流动性;第4节介绍了采用运动估计和轮廓分析进行目标检测;第5节描述了人群密度估计的问题和改进方法;第6节介绍完整算法过程,然后分析结果得出结论;第7节总结本文研究内容。
2 相关研究
目标检测关键是从背景中分离运动目标,就是重建背景,然后将不属于背景的目标进行分类,2.1节介绍了这种背景模型方法。另一种是根据像素点运动产生的帧间区别来提取前景,2.2节做了粗略的介绍。目标检测的第二步是验证检测的前景是人物,2.3节介绍了人体模型检测方法。2.4节介绍了一些更加倾向于进行人头检测的方法。2.5节介绍有关人群密度估计的方法。
2.1 背景建模
在运动检测和目标跟踪的过程中,目标的分离是最关键的。帧差法是通过当前帧和参考帧之间的差异来检测目标的基本方法[25],可以设置全局阈值[46]或者多阈值[62]。此外通过图像累积差异来分离背景和前景[42]。Pfinder[85]采用多类统计像素单高斯模型来重建像素点的值,从而保存了天然的图像噪声,接着自适应背景建模的概念被引入,开始使用混合高斯(MOG)[26,74],每个像素值与一个MOG模型匹配(背景像素在混合模型中有更多的权重),新的高斯成分会代替匹配可能性最小的成分,根据像素点的均值和方差,不与任何模型相匹配的像素点会被判定为前景。这是背景建模中最普遍采用的方法之一。
MOG被推广采用了核密度估计(KDE)[21],就是将像素点最近的观测值作为核。研究到这一步,只是依靠像素点的灰度值来重建背景,后来有人利用像素点的颜色信息来建立高斯模型[85,95],但是值得关注的是当在阴影投下和不均匀光照等无约束环境中时,像素点色彩信息改变是非常显著的。当然也有人利用特征值来重建背景[60],特征值取降序中的方差,因此像素点区域的特征值代表着波动的高低程度。还有人采用高斯平均、像素空间相关性和像素值的双峰分布(不论是前景还是背景)[27-29]来进行背景建立。应该指出的是,这些方法都使用最近的像素观测值。相反的,有人对于每一个像素点将已存在过或相邻点的像素值和新像素值之间的欧氏距离进行计算并存储[7]。背景建模的缺点是,系统需要提供学习的场景。在一般情况下,场景模型学习取决于学习率和样本帧(没有对象)。当背景具有大的动态范围,由于大量的目标和遮挡目标的存在,背景建模将需要一个相对较长的时间。
2.2 运动估计
不同于背景建模方法,运动估计是依靠帧间运动来实现的,场景中物体的运动导致像素点的信息的变化。光流法就是通过场景中目标一部分信息变化来测量速度。基于二维向量进行运动估计的方法[8]分为4种:(1)梯度判别;(2)区域判别;(3)能量判别;(4)相位判别。梯度判别法[34,50,59,79]是利用时空上的变化得到像素点速度;区域判别法是利用窗口区域最大化强度相似度来匹配像素点[5,70];能量判别法是利用空间窗口和傅里叶频率域纹理特征来估计窗口中的功率来计算光流速度[32,33],相位判别法是基于轮廓跟踪来计算速度。若是密集的光流[34]需要考虑到了全方位场景并估计运动形式,正规化使得运动矢量估计是流畅的;若是稀疏的光流[50]利用一个窗口平均像素值来估计运动形式。运动估计方法的不足是,只有当存在一个运动时所开发的技术才是适用的,长时间不动的目标无法被检测到。
2.3 人体建模
为了克服人类的非相干运动干扰[2],基于区域形状检测的分析法被广泛用于人物检测和分类。其中利用三维模型去解释前景[93,49]解决了人群遮挡问题,同样以形状和颜色特征外观为基础的模型也是适用的。一些人用模板显示人的形态信息[11,20,24,97],其中基于小波变换的模板也被采用过[61],这些信息常用于进行局部匹配,如头、手、躯干和腿的形状匹配。形态模型也包括点、轮廓形状、关节和骨骼模型[10],一般有效的外观模型(AAM)结合了空间形状和部分纹理、颜色、边缘特征。AAM是适用于人脸识别、眼球追踪和医学图像分割的模型。然而,人类模型匹配需要确切的模型、目标的结构、原有颜色和重复出现的特征。
2.4 人头检测
在大多数的监视和跟踪系统中,一般假定人在直立行走,跟踪人的突出特点之一就是检测头部。由于大部分的身体部位遵循关节运动,而每个人头部保持着稳定的运动形状,因此在这方面,人们跟踪计数采用头部检测方法[29,36,39,40,55,57,58]。基于头部检测的方法也可用于估计人群密度,在人群拥挤情况下,头部检测可以很好的协助进行定位个体,例如基于全方位头部检测和二维高斯核的回归模型[66]可以运用于人群拥挤状况下的密度估计,梯度方向的感兴趣点被用来形成一个二进制图像。也有人利用近紫外渠道的六个方向梯度强度作为特征用于头部检测[75]。然而,头部的可见性取决于摄像头的角度和遮挡现象严重程度,头部检测试用完整的顶部视图能得到更好的结果,而倾斜的视角会受到遮挡现象的影响。此外,其他基于头部检测的密度估计方法依赖于头部检测准确度,而目前检测率是很低的。
2.5 密度估计
大多数的人群密度估计方法使用的局部纹理特征和全方位特征或使用运动信息提取的前景像素,将前景像素特征映射到人群密度。灰度共生矩阵(GLDM)、闵可夫斯基分形维数(MFD)、平移不变的正交切比雪夫矩(TIOCM)等利用纹理特征并使用自组织映射来归类人群密度为五类(极低,低,中,高和非常高)[64]。灰度共生矩阵(GLDM)的局部和全局的层次特征和支持向量机(SVM)被用于对异常人群密度检测分类[86],Kanade–Lucas–Tomasi(KLT)[50]提取的跟踪特征通过聚类来评价公共场所人群密度[3],统计纹理测度如对比度、均匀性、能量、熵和梯度方向等的共生矩阵(GOCM)与nu;-支持向量回归(nu;-SVR)结合进行估计密度[52,53],高斯回归过程中使用几何,边缘和纹理特征可以很好的进行密度估计[12]。
利用背景建模进行密度估计是基础的方法,也可以在文献中找到,如斑点面积、Harris角点,KLT特征点,轮廓,轮廓周长、轮廓周长比、canny边缘和分形维数输入作为多变量线性回归模型[54]的变量,也有将神经网络与前景像素和形态学运算相结合,对人群密度进行了估计[37]。随时间积累的前景像素由纹理特征等四个方向对密度进行估计:使用0,45,90和135创建灰度共生矩阵(GLCM)和统计特征(能量、熵、同质化,对比)[73]。
相反,人群建模也使用运动估计,随后马尔可夫的随机场(MRF)来定位目标的位置并应用最小二乘法来减少邻域检索空间[37]。此外,也有人提出了利用离散余弦变换(DCT)得到运动频率结合SVM进行估计密度[38],还有人利用鲁棒性运动速度加快点(SURF),组成一个集合作为特征输入ε-SVM进行密度估计。上述方法都需要样本训练,若场景变化则需要重新训练分类器。
在本文中,我们提出的人群密度估计,使用运动估计法和层次聚类法。Willick和Yang [83]表明Horn 和 Schunk[34] 的运动估计算法要比Nagel 的[59]好。此外 Lucas和Kanade[50]窗口大小的选择影响了流动矢量的确定,相对于密集的光流,非刚性运动人体可能更容易产生噪声向量。在这些研究中,路径选择的人群密度估计是:1.视频输入→2.滤波器预处理→3.检测多目标→4.密度估计→5.得到人数。我们假定可以直接提取校准过摄像视频并且只有人物目标属于前景,效果图如图2~4所示是从三个数据库(MCG,PETS 2009和UCSD)提取的样本帧。
图2 MCG视频序列
图3 PETS 2009视频序列
图4 UCSD视频序列
3 流体法
设 表示帧图像中一个矩形区域,,则人群密度估计问题看表示为:
|
|
(1) |
其中是矩形区域内的人群密度。于是,估计人群密度的问题可以转化为估计给定区域人群人数问题,更进一步说,就是统计给定区域运动目标数量。
- 首先非线性低成本的光学筒或枕形失真用镜头进行每一帧校正,此外,从三维到二维中心投影成像通过透视进行校正。
-
接下来是视频帧预处理,通过应用合适的滤波器除去视频噪声,如色度噪声,模糊场景和散斑噪声。 剩余内容已隐藏,支付完成后下载完整资料
资料编号:[147496],资料为PDF文档或Word文档,PDF文档可免费转换为Word
以上是毕业论文外文翻译,课题毕业论文、任务书、文献综述、开题报告、程序设计、图纸设计等资料可联系客服协助查找。

