
英语原文共 15 页,剩余内容已隐藏,支付完成后下载完整资料
突出对象检测:基准
Ali Borji, Ming–Ming Cheng, Huaizu Jiang and Jia Li
摘要:我们广泛地比较,定性和定量地比较了6个具有挑战性的数据集中的40个最先进的模型(28个突出物体检测,10个固定预测,1个目标和1个基准),用于基准突出物体检测和分割方法。从迄今为止的结果来看,我们的评估显示,在过去几年中,在精度和运行时间方面均保持了快速的进展。该基准的最大竞争者显着优于两年前确定为最佳基准的模式。我们发现,专门针对突出物体检测而设计的模型通常比密切相关的领域更好,而反之则提供了一个精确的定义,并建议对这个问题进行适当的处理,将其与其他问题区分开来。特别地,我们分析了中心偏差和场景复杂度对模型性能的影响,其中与最先进模型的硬实例一起为构建更具挑战性的大规模数据集和更好的显着性模型提供了有用的提示。最后,我们提出了解决诸如评估分数和数据集偏差等几个开放问题的可能解决方案,这也提示了快速增长的突出物体检测领域的未来研究方向。
关键词:显着的对象检测;显着性;显性显着性;视觉注意;感兴趣的领域;客观性;分割;趣味性;重要性;眼睛运动
一、引言
视觉注意是人类视觉系统令人惊讶的能力,只有选择性地处理显着的视觉刺激细节,已经被多个学科,如认知心理学,神经科学和计算机视觉[2] - [5]。在认知理论(例如,特征整合理论(FIT)[6],引导搜索模型[7],[8])和早期关注模型(例如Koch和Ullman [9]和Itti等[10]已经提出了数百个计算显着性模型来检测来自图像和视频的显着视觉子集。
尽管心理和神经生物学的定义,视觉显着性的概念在计算机视觉领域变得模糊。一些视觉显着性模型(例如,[3],[10] - [16])旨在预测人类固定作为测试其显着性检测准确性的方法,而其他模型[17] - [19]经常由计算机视觉应用程序驱动,如内容感知图像调整大小和照片可视化[20],试图识别突出区域/对象并使用明确的显着判断来评估[21]。虽然两种类型的显着性模型预计可互换使用,但由于显着性检测的不同目的,它们的生成显着性图实际上显示出显着不同的特征。例如,固定预测模型通常弹出稀疏的blob样突出区域,而显着对象检测模型通常会产生平滑的连接区域。一方面,检测大的突出区域常常导致严重的假阳性用于固定预测。另一方面,弹出的稀疏突出区域在检测突出区域和对象方面造成了大量的漏洞。
为了分离这两种类型的显着性模型,在本研究中,我们提供了一个精确的定义,并建议对突出物体检测的适当处理。一般来说,一个突出物体检测模型首先要检测一个场景中突出显着的物体,第二个是对整个物体进行分割。通常,模型的输出是一个显着图,其中每个像素的强度表示其属于显着对象的概率。从这个定义,我们可以看出,这个问题本质上是一个数字/地面分割问题,目标是仅从背景分割显着的前景对象。请注意,它与传统的图像分割问题略有不同,其目的是将图像分解为感知相干区域。
突出对象检测模型的价值在于其在许多领域的应用,如计算机视觉,图形和机器人。例如,这些模型已经成功应用于诸如对象检测和识别[22] - [29],图像和视频压缩[30],[31],视频摘要[32] - [34],照片拼贴/ 媒体重新定位 / 种植/拇指钉 [20],[35],[36],图像质量评估[37] - [39],图像分割[40] - [43]图像采集浏览[44] - [47],图像编辑和操纵[48] - [51],视觉跟踪[52] - [58],对象发现[59],[60]和人机交互[61] ],[62]。突出物体检测领域发展非常快。自从我们两年前的基准测试以来,已经提出了许多新的模型和基准数据集[1]。然而,目前尚不清楚新算法对以前的模型和新数据集的影响。在这个领域有什么真正的改进,或者我们只是将模型适合数据集?在新的基准数据集上测试旧的高性能模型的性能也是有趣的。 [28]最近对突出物体检测模型进行了详尽的回顾。
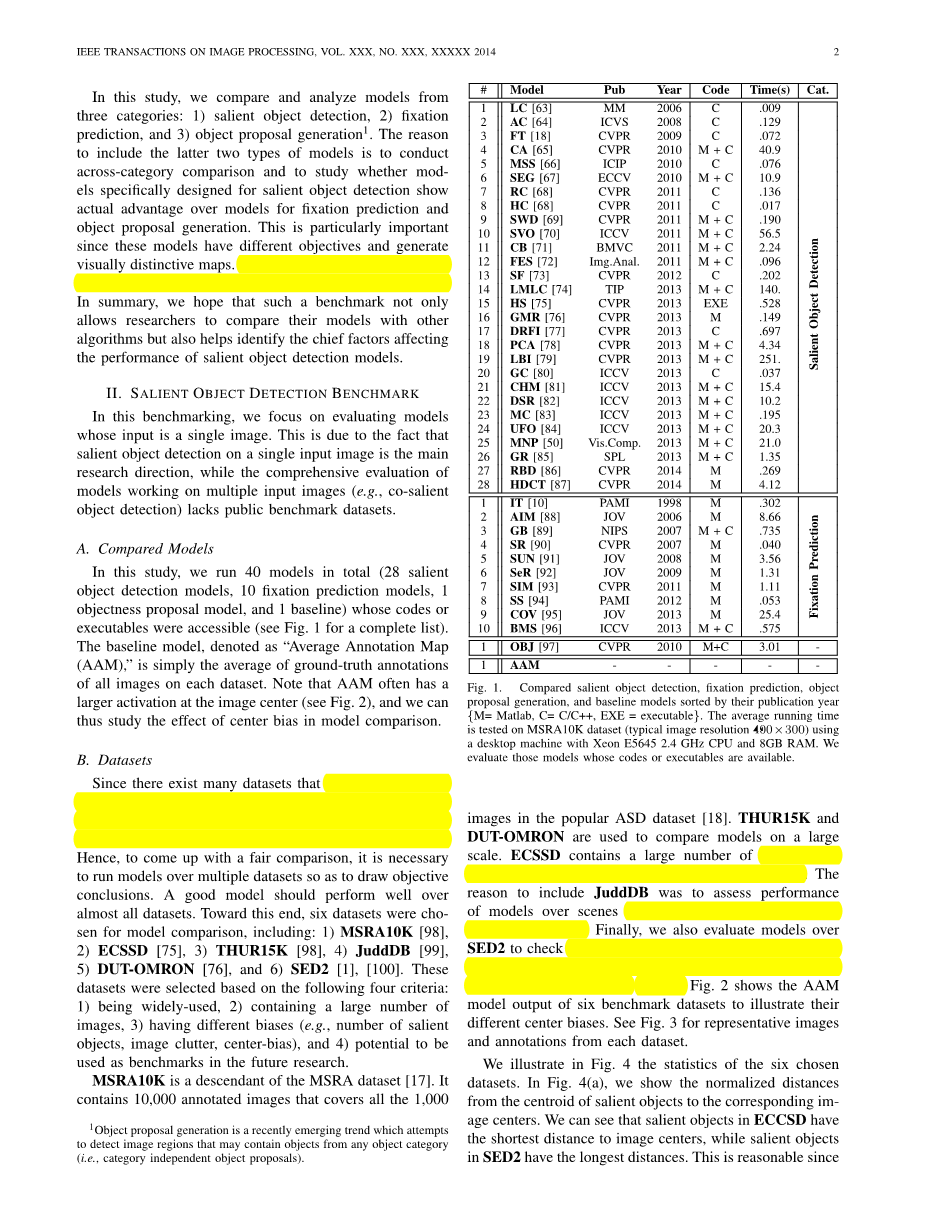
在这项研究中,我们比较和分析了三个类别的模型:1)显着对象检测,2)固定预测,3)对象建议生成[对象提议生成是一种最近出现的趋势,尝试检测可能包含对象的图像区域任何对象类别(即类别独立对象提案)。包括后两种类型的模型的原因是进行跨类别比较,并研究专门用于突出物体检测的模型是否显示与固定预测和对象建议生成模型相比的实际优势。这是特别重要的,因为这些模型具有不同的目标并产生视觉上独特的地图。我们还包括一个基准模型来研究中心偏差对模型比较的影响。总而言之,我们希望这样一个基准测试不仅可以使研究人员将其模型与其他算法进行比较,还有助于确定影响突出物体检测模型性能的主要因素。
二、突出对象检测基准
在这个基准测试中,我们专注于评估其输入是单一图像的模型。这是因为单个输入图像上的显着对象检测是主要的研究方向,而对多个输入图像(例如,共显着对象检测)工作的模型的综合评估缺少公共基准数据集。
A.比较模型
在这项研究中,我们总共运行了40个模型(28个突出物体检测模型,10个固定预测模型,1个对象建议模型和1个基线),其代码或可执行文件可访问(参见图1的完整列表)。表示为“平均注释图(AAM)”的基线模型仅仅是每个数据集上所有图像的地面事实注释的平均值。注意,AAM在图像中心通常具有较大的激活(见图2),因此我们可以研究中心偏差对模型比较的影响。
B.数据集
由于存在许多不同图像数量的数据集,每个图像的对象数量,图像分辨率和注释形式(边界框或准确区域掩码),所以模型可能会在数据集之间排序不同。因此,为了得出一个公平的比较,有必要运行多个数据集的模型,以得出客观的结论。一个好的模型应该能够在几乎所有的数据集中表现良好。为此,选择了6个数据集进行模型比较:1)MSRA10K [98],2)ECSSD [75],3)THUR15K [98],4)JuddDB [99],5)DUT-OMRON [76] ,和6)SED2 [1],[100]。这些数据集是基于以下四个标准进行选择的:1)被广泛使用,2)包含大量图像,3)具有不同偏差(例如显着数量,图像杂波,中心偏差)和4 )潜力被用作未来研究的基准。
MSRA10K是MSRA数据集的后代[17]。 它包含10,000个注释图像,涵盖了流行的ASD数据集[18]中的所有1,000张图像。 THUR15K和DUT-OMRON用于大规模比较型号。 ECSSD包含大量语义有意义但结构复杂的自然图像。 包括JuddDB的原因是评估模型与具有高背景杂波的多个对象的场景的性能。 最后,我们还评估SED2模型,以检查突出物体检测算法是否能够对包含多个突出物体的图像(即SED2中的两个)进行良好的表现。 图。 图2显示了六个基准数据集的AAM模型输出,以说明其不同的中心偏差。 见图3中代表每个数据集的代表性图像和注释。
我们在图4中统计了六个选择的数据集。在图4(a)中,我们显示了从显着对象的质心到相应图像中心的归一化距离。我们可以看到,ECCSD中的突出物体与图像中心距离最短,而SED2中的显着物体距离最远。这是合理的,因为SED2中的图像通常有两个物体对齐在相对的图像边界周围。此外,我们可以看出,JuddDB中的显着对象的空间分布具有比其他数据集更大的多样性,表明该数据集具有较小的位置偏差(即显着对象的中心偏差和背景区域的边界偏倚)。
在图4(b)中,我们的目标是在六个基准数据集中显示图像的复杂性。为此,我们应用Felzenszwalb等人的分割算法看看分别从每个图像的显着对象和背景区域平均获得多少个超像素(即均匀区域)。以这种方式,我们可以使用这个措施来反映基准的挑战性,因为大型超像素通常表示复杂的前景对象和混乱的背景。在图4(c)中,我们可以看出,JuddDB是最具挑战性的基准,因为它从每个图像的背景中平均拥有493个超像素。相反,SED2在前景和背景区域中包含较少数量的超像素,这表明该基准测试中的图像通常包含统一的区域,易于处理。
在图4(c)中,我们演示了这些基准的平均对象大小,而每个对象的大小由相应图像的大小进行归一化。我们可以看到,MSRA10K和ECCSD数据集具有较大的对象,而SED2具有较小的对象。特别地,我们可以看到,一些基准包含有限数量的具有大前景对象的图像区域。通过共同考虑中心偏置特性,在这些图像上实现高精度变得非常容易。
C.评估措施
有几种方法来衡量模型预测和人类注释之间的协议[21]。一些指标评估标记区域之间的重叠,而其他指标则尝试评估绘制形状与对象边界的准确性。此外,一些指标也试图考虑边界和形状[102]。
在这里,我们使用三个通用的,标准的和易于理解的方法来评估突出物体检测模型。前两个评估指标基于主观注释与(c)JuddDB(d)DUT-OMRON之间的重叠区域
突出预测,包括精确召回(PR)和接收机操作特性(ROC)。从这两个指标来看,我们还报告了共同考虑召回率和精度的F-Measure和AUC,这是ROC曲线下的面积。此外,我们还使用直接计算估计显着性图和地面标注之间的平均绝对误差(MAE)的第三种方法。为了简化起见,我们使用S表示归一化为[0,255]的预测显着图,G表示显着对象的地面二进制掩码。对于二进制掩码,我们使用| ·|以表示掩码中非零条目的数量。精密召回(PR)。对于显着图S,我们可以将其转换为二进制掩码M,并通过将M与地面真值G进行比较来计算精度和回归:
从这个定义可以看出,S的二值化是评估的关键一步。 通常,有三种流行的方式来执行二值化。 在第一个解决方案中,Achanta等人 [18]提出了二值化S的图像依赖自适应阈值,其计算为S的平均显着性的两倍:
, (2)
其中W和H分别是显着图S的宽度和高度。二分法S的第二种方法是使用从0变为255的固定阈值。在每个阈值上,一对二值化的第三种方法是使用SaliencyCut算法[68]。 在该解决方案中,通常导致良好的召回但相对较差精度的松散阈值被用于产生初始二进制掩码。 然后该方法迭代地使用GrabCut分割方法[103]逐渐优化二进制掩码。 最终的二进制掩码用于重新计算精度回忆值。F度量。 通常情况下,Precision和Recall都不能全面评估显着性图的质量。 为此,F度量被提出为具有非负重量beta;的加权谐波平均值:
. (3)
如许多突出物体检测工作(例如[18],[68],[73])所提出的,beta;2被设置为0.3以提高对Precision值的重要性。加权精度超过召回的原因是召回率不如精度那么重要(参见[104])。例如,通过将整个区域设置为前景,可以轻松实现100%的召回。
根据显着图二值化的不同方式,有两种计算F-Measure的方法。当使用自适应阈值或GrabCut算法进行二值化时,我们可以为每个图像生成单个Fbeta;,并将最终F-Measure计算为平均Fbeta;。当使用固定阈值时,得到的PR曲线可以通过其最大Fbeta;进行评分,这是检测性能的一个很好的总结(如[105]中所提出的)。如(3)所定义,F-Measure是精度和调用的加权调和平均值,因此具有与精度和回忆值相同的值边界,即[0,1]。
接收器工作特性(ROC)曲线。除了Precision,Recall和Fbeta;之外,我们还可以在使用一组固定值来显示显着图二值化时报告放样率(FPR)和真阳性率(TPR)
阈值: (4)
其中Mmacr;和Gmacr;分别表示二进制掩模M和地面真相的相反。 ROC曲线是通过改变阈值Tf的TPR与FPR的曲线图。ROC曲线下面积(AUC)得分。虽然ROC是模型性能的二维表示,但AUC将该信息提炼为单个标量。顾名思义,它被计算为ROC曲线下的面积。一个完美的模型将获得1的AUC,而随机猜测将获得约0.5的AUC。
平均绝对误差(MAE)得分。上面引入的基于重叠的评估措施不考虑真正的负显着性分配,即正确标记为不显着的像素。这有利于成功地将显着性分配给显着像素但不能在成功检测非显着像素但在确定显着像素中产生错误的方法上检测非显着区域的方法[73],[80]。此外,在一些应用场景[106]中,加权,连续显着图可能比二进制掩码更重要。为了进行更全面的比较,我们还评估了连续显着图S和二值地面实数G的平均绝对误差(MAE),两者都在[0,1]的范围内归一化。 MAE评分定义为:
请注意,这些分数有时不符合对方。例如,图5显示了使用PR和ROC指标的ECSSD两种模型的比较。虽然ROC曲线(因此大致相同的AUC)没有很大差异,但使用PR曲线(因此具有较高的Fbeta;),一个模型显然得分更好。 [107]已经广泛研究了中华民国和公报措施之间的差距。请注意,在评估突出物体检测模型中,阴性例子(非临时像素)的数量通常要比阳性实例(显着对象像素)的数量大得多。因此,PR曲线比ROC曲线更具信息性,并且可以对算法的性能提出过分乐观的观点[107]。因此,我们主要基于PR曲线得分(即F-Measure分数)的结论,并报告综合比较的其他得分和促进特定应用要求。值得一提的是积极研究正在进行中,以找出更好的测量突出物体检测和分割模型的方法(例如[108])。
D.模型的定量比较
我们使用所有评估指标来评估不同模型对六个数据集产生的显着图:
1) 图6,图7表示PR和ROC曲线;
2)图 8,图 9表示AUC和MAE评分; 3)图10显示了所有模型的Fbeta;分数[使用三种分割方法,包括自适应阈值,固定阈值和SaliencyCut算法。在PR和ROC曲线方面,DRFI模型惊人地胜过了六个具有较大利润率的基准数据集的所有其他模型。此外,RBD,DSR和MC(分别具有蓝色,黄色和品红色的实线)实现了更好的性能,并且性能略好于其他型号。
使用F度量(即Fbeta;),五个最佳模型是:DRFI,MC,RBD,DSR和GMR,其中DRFI模型始终赢得所有5
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[26412],资料为PDF文档或Word文档,PDF文档可免费转换为Word

